About
ONNX Runtime is an open source project that is designed to accelerate machine learning across a wide range of frameworks, operating systems, and hardware platforms. It enables acceleration of machine learning inferencing across all of your deployment targets using a single set of API. ONNX Runtime automatically parses through your model to identify optimization opportunities and provides access to the best hardware acceleration available.
ONNX Runtime also offers training acceleration (in preview), which incorporates innovations from Microsoft Research and is proven across production workloads like Office 365, Bing and Visual Studio.
Join us on Github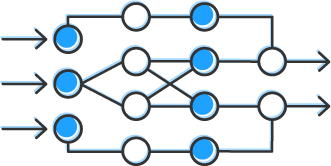
Optimization and acceleration
Run any ONNX model using a single set of inference APIs that provide access to the best hardware acceleration available. Built-in optimization features trim and consolidate nodes without impacting model accuracy. Additionally, full backwards compatibility for ONNX and ONNX-ML ensures all ONNX models can be inferenced.
API and platform support
Take advantage of the benefits of ONNX Runtime without changing your technology stack. Access ONNX Runtime using your preferred API — C#, C++, C, Python, or Java. Support for Linux, Windows and Mac allows you to build and deploy applications without worry.
Continuous community innovation
Our community of partners and contributors drives constant innovation. Partners provide ONNX compatible compilers and accelerators to ensure models are as efficient as possible. Our contributor community improves ONNX Runtime by contributing code, ideas and feedback. Join us on GitHub.
Design principles
ONNX Runtime abstracts custom accelerators and runtimes to maximize their benefits across an ONNX model. To do this, ONNX Runtime partitions the ONNX model graph into subgraphs that align with available custom accelerators and runtimes. When operators are not supported by custom accelerators or runtimes, ONNX Runtime provides a default runtime that is used as the fallback execution — ensuring that any model will run.